爬取牛客网的帖子,获取一些感兴趣的信息,比如职位内推等。
为获得每日最新数据,系统使用增量更新,老数据保存到mysql数据库中用于去重,使用NLP分类模型进行内容筛选,过滤掉无关内容,每日新增的数据发邮件提醒,使用crontab定时任务每天自动运行,邮件效果如下图所示:

MySQL数据表结构如下
1 | CREATE TABLE IF NOT EXISTS `newcoder_search`( |
python爬虫
爬取并解析数据
1 | import requests |
数据落库去重
将数据存入数据库,根据id去重,如果id不存在则insert,如果id已存在但editTime 有变化则update, 否则是重复的过滤掉
1 | import pymysql |
邮件发送
将新创建的帖子与原有的但更改过的帖子区分开发送
1 | import smtplib |
集成控制
1 |
|
内容筛选
直接爬下来的帖子既包含招聘信息,又包含求职者发布的面经、讨论贴等其他内容,现在希望过滤掉那些无关的帖子。
第一版只写了一个根据关键词和正则表达式进行过滤的功能,用户指定skip_words,凡包含这里面的关键词的都会被过滤。过滤方法如下:
1 | import re |
但这种方法也不是很准,还是会有漏网之鱼,怎么才能实现更精准的过滤呢?
一种可能的方案是训练一个NLP分类模型进行过滤,但这需要大量数据进行训练,目前我已爬取牛客网上历史数据4万多条,但需要标注数据,不太想人工去标数据,这个计划暂时搁置,代码和历史数据已开源在github newcoder-crawler
**[更新]**:最后还是忍不住想玩一下,花了一周时间,训练了一个帖子分类模型进行过滤,详细构建过程见如何从零开始构建一个网络讨论帖分类模型?,模型地址:roberta4h512.zip.
下载下来后解压,将roberta4h512文件夹放到与爬虫脚本同级目录下,模型推理的代码如下:
1 | from transformers import AutoTokenizer, AutoModelForSequenceClassification |
最后,稍微改一下run函数,加入模型过滤的逻辑即可,另外还有一些人会把一个信息重复发布多份,这里加入一个根据内容进行去重的逻辑,修改后的run函数如下:
1 |
|
编写shell脚本,使用crontab自动运行
代码希望每天运行一次, 如果每次都手动运行的话,使用体验就很不好了,最好是放在服务器中,弄个croontab定时任务,每天自动运行一次。把启动的命令写成shell脚本如下:
shell脚本newcoder.sh内容如下:
1 | source /root/anaconda3/bin/activate base |
crontab配置
1 | crontab -l # 查看已经存在的定时任务 |
这里crontab -e新加配置内容如下,每天18:30运行一次:
1 | 30 18 * * * bash /root/chadqiu/crawler/newcoder.sh |
cron配置语法规则:
5个位置含义如下:
1 | Minute Hour Day Month Dayofweek command |
1 | “*”代表取值范围内的数字, |
Nacos配置中心
刚才的main函数里有很多配置需要写,特别是过滤词、接收邮箱列表等可能会经常改变,每改一次就得重新改代码非常麻烦,因此引入了Nacos注册中心,将keywords, skip_words, db_config, mail_config这四个配置变量放在Nacos中,这样就可以动态修改了,在Nacos中配置为json格式,如下图所示
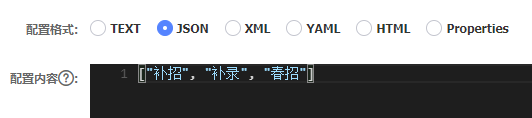
代码稍作修改,加入一个get_config函数,并修改一下main函数,修改的代码如下:
1 | import nacos |
将上面两份代码整合后的完整代码见 github