1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| from bs4 import BeautifulSoup
import urllib.request
import re
import time
import traceback
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/90.0.4430.93 Safari/537.36'}
def get_paper_page(url):
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req, timeout=100)
html=res.read().decode('utf-8')
soup=BeautifulSoup(html)
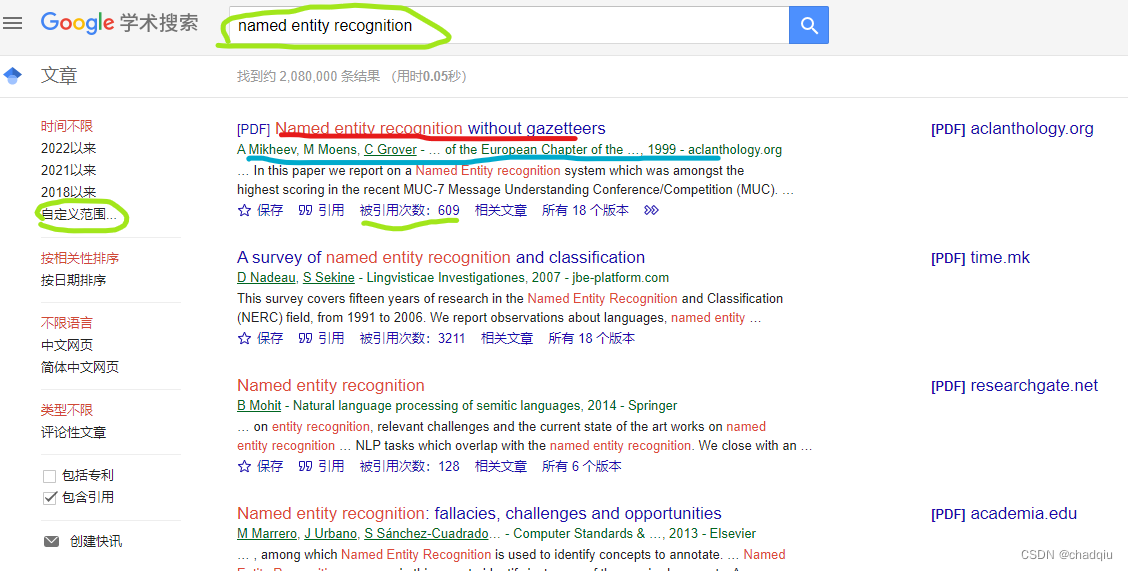
data = [[div.select('.gs_rt > a')[0].text, div.select('.gs_fl > a')[2].string, re.search("- .*?\</div>", str(div.select('.gs_a')[0])).group()[1:-6].replace("\xa0", ""), div.select('.gs_rt > a')[0]["href"]] for div in soup.select('.gs_ri')]
data = [[x[0], int(x[1][6:]) if x[1] != None and x[1].startswith("被引用次数") else 0, x[2], x[3]] for x in data]
return data
def save_paper_list(data, file_name):
data = pd.DataFrame(data, columns=['paper title', 'reference', 'publish info', 'url'])
writer = pd.ExcelWriter(file_name)
data.to_excel(writer, index=False, encoding='utf-8', sheet_name='Sheet1')
writer.save()
writer.close()
def get_paper_list_by_keywork(keyword, start_year = None, end_year = None, max_capacity = 100, debug_mode = False, save_file = "paper_list.xlsx", retry_times = 3):
keyword = re.sub(" +", "+", keyword.strip())
url_base = 'https://scholar.google.com/scholar?hl=zh-CN&as_sdt=0%2C5'
url_base = url_base + '&q=' + keyword
if start_year != None:
url_base += "&as_ylo=" + str(start_year)
if end_year != None:
url_base += "&as_yhi=" + str(end_year)
start = 0
data = []
while start < max_capacity:
url = url_base + "&start=" + str(start)
start += 10
print(url)
for i in range(retry_times):
try:
data.extend(get_paper_page(url))
break
except Exception as e:
if i < retry_times -1:
print("error, retrying ... ")
else:
print("error, fail to get ", url)
if debug_mode:
traceback.print_exc()
time.sleep(20)
time.sleep(10)
print(data)
save_paper_list(data, save_file)
if __name__ == "__main__":
get_paper_list_by_keywork(" named entity recognition ", start_year=2020, max_capacity=100, debug_mode=False, save_file = "paper_list.xlsx")
print("end")
|